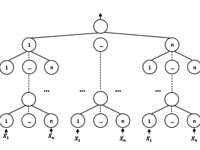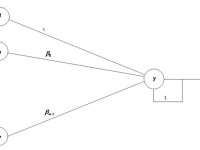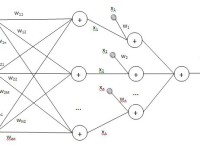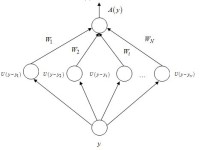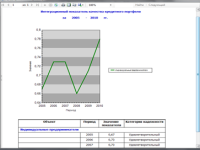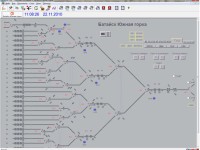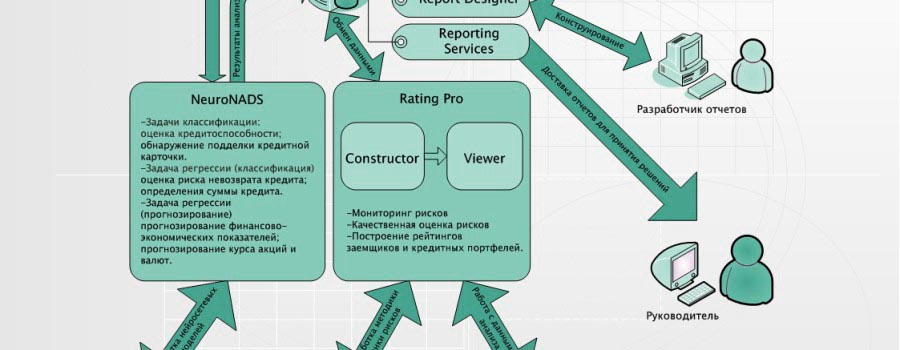
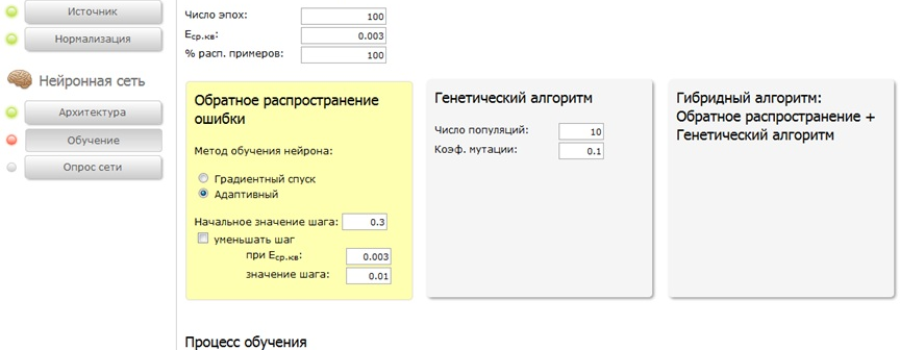
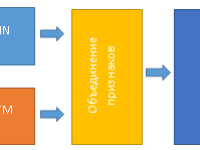
О разработке гибридных нейросетевых моделей в задачах прогнозирования временных рядов
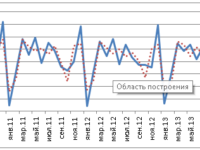
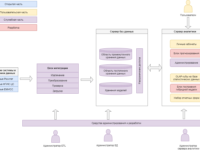
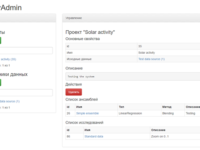
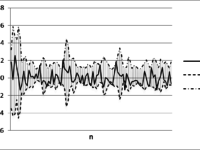
Автор статьи: Е.В. Пучков Последнее время нейронные сети продемонстрировали впечатляющие результаты при решении прикладных задач анализа данных. Как и любой метод, искусственные нейронные сети имеют свои достоинства и недостатки. К главному достоинству нейронных сетей относится их способность эффект... »