Разработка системы хранения ансамблей нейросетевых моделей
Авторы статьи: Пучков Е.В., Терехов С.
Введение
Важным инструментов в работе специалиста по анализу данных и машинному обучению является программное обеспечение для организации экспериментов. Прежде всего это связано с большим количеством этапов в обработке данных и спецификой их осуществления. В ходе работы был спроектирован и разработан прототип системы хранения ансамблей нейросетевых моделей, обеспечивающий структурированное хранение данных на различных этапах решения задачи прогнозирования временных рядов. Рассмотрены модель данных, архитектура системы хранения и механизмы поступления и перераспределения информации в ней. Разработана модель классов для программного взаимодействия с хранилищем. Для хранения данных об объектах и связей между этими объектами была использована MySQL, а для хранения временных рядов - нереляционная база данных InfluxDB. Создан пользовательский интерфейс с возможностями наглядного отображения данных и удобного взаимодействия с хранилищем ансамблей нейросетевых моделей. Апробация системы проводилась на примере задачи прогнозирования солнечной активности за период с января 1700 года по февраль 2015 года. Проведенный эксперимент с применением рекуррентной сети LSTM показал, что ошибка ансамбля нейросетевых моделей ниже, чем ошибка каждой отдельно взятой нейросетевой модели. LSTM построена с применением библиотеки Keras, для формирования ансамбля использован подход Blending. Результаты проделанной работы показывают перспективность разработки, обеспечивающей высокую степень интеграции в расширяемые программные продукты на языке Python. Разработка полнофункциональной системы позволит не только организовать процесс анализа данных, но и повысить качество результирующих моделей за счет автоматизации процесса формирования ансамблей.
В последнее время среди специалистов по анализу данных и машинному обучению набирает популярность программное обеспечение для организации исследований. Прежде всего это связано с большим количеством этапов в обработке данных и спецификой их осуществления. Можно выделить такую библиотеку как, Sacred [1], которая позволяет организовать эксперименты без привязки к конкретным моделям, данные параметров моделей и результаты можно сохранить в базе данных. В библиотеке Hyperopt [2] акцент делается на оптимизации параметров моделей. FGLab [3] аналитику позволяет запустить свои модели на распределенной системе с возможностью сохранять результаты экспериментов и их параметры в базе данных. Для сложных вычислительных задач с применением Hadoop, которые могут длится дни или недели, подойдет Luigi [4]. Данный пакет позволяет организовать и управлять многочисленными вычислительными задачами в одном месте. Последние две системы имеют интерфейс для визуализации результатов и информации по задачам.
Заключающим этапом в решении задачи машинного обучения является построение ансамбля моделей, поскольку в некоторых случаях оптимальное решение может быть получено с применением ансамбля нескольких различных моделей. Большое количество источников показывает практическую значимость применения ансамбля в решении прикладных задач [5, 6, 7]. Стоит также отметить, что очень часто в таких ансамблях используют нейросетевые модели. Но что еще примечательно, что построение ансамбля только из нейросетевых моделей в некоторых задача дает преимущество [8,9,10]. В связи с этим возникает проблема хранения данных на этапах моделирования, в том числе данных самих моделей и ансамблей, построенных с помощью них. Проведенный обзор систем организация экспериментов показал, что существующие системы не решают такую проблему в явном виде.
Целью данной работы является проектирование и разработка системы хранения ансамблей нейросетевых моделей, обеспечивающей структурированное хранение данных на различных этапах решения задач прогнозирования временных рядов. Разработка хранилища позволит не только организовать процесс анализа данных, но и повысить качество результирующих моделей за счет автоматизации процесса формирования ансамблей.
Работу можно разделить на четыре основных части:
- разработка модели данных;
- разработка архитектуры системы хранения;
- разработка пользовательского интерфейса;
- тестирование системы на реальных данных.
Для задач прогнозирования временных рядов принято использовать два типа ИНС: рекуррентные сети (RNN) [11] и различные сети прямого распространения с задержкой по времени (TLFN) [12]. Задержку по времени также можно применять и для рекуррентных сетей [13]. В работе при решении задачи прогнозирования временного ряда будет использована LSTM (Long Short-Term Memory — долгая краткосрочная память). Рекуррентные нейронные сети, основанные на этом подходе, получили большое распространение при решении задач распознавания рукописного текста, моделирование языка, машинного перевода, обработки аудио, видео и изображений, анализа тональности и классификации текстов, прогнозирования временных рядов.
При решении сложных задач классификации, регрессии, а также прогнозирования временных рядов часто оказывается, что ни один из алгоритмов не обеспечивает желаемого качества восстановления зависимости. В таких случаях имеет смысл строить композиции алгоритмов (ансамбли), в которых ошибки отдельных алгоритмов взаимно компенсируются. Для задачи прогнозирования временных рядов подойдут такие подходы как голосование и cтекинг (stacking). Данные подходы подразумевают формирование ансамбля из моделей, полученный на одинаковых данных, что подходит для временных рядов, в отличие от подходов, таких как бустинг (boosting) и бэггинг (bagging), где данные для базовых алгоритмов используются разные.
Наиболее известные корректирующие операции голосования:
- простое голосование:
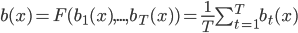 ;
; - взвешенное голосование:
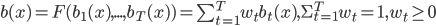 ;
; - смесь экспертов:
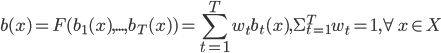 .
.
Простое голосование — это лишь частный случай взвешенного голосования, а взвешенное голосование является частным случаем смеси экспертов.
Основная идея стекинга и его разновидности блендинга (blending) заключается в использовании базовых алгоритмов для получения предсказаний (метапризнаков) и использовании их как признаков для некоторого обобщающего алгоритма (метаалгоритма). Иными словами, основной идеей стекинга является преобразование исходного пространства признаков задачи в новое пространство, точками которого являются предсказания базовых алгоритмов [14].
Разработка модели данных и архитектуры системы хранения
Для реализации поставленных задач необходим следующий набор программных средств:
- реляционная база данных для хранение данных об объектах и связей между этими объектами;
- нереляционная база данных для хранения временных рядов;
- язык программирования для реализации логики системы хранения;
- сопутствующие программные пакеты, в том числе реализующие LSTM.
В качестве реляционной СУБД была использована MySQL [15]. Для хранения временных рядов современное решение – InfluxDB [16]. Для программирования логики хранилища нейросетевых моделей выбран Python версии 2.7.11 и следующие свободно распространяемые пакеты:
- numpy – для работы с массивами [17];
- sklearn – библиотека для анализа данных [18];
- cherrypy – библиотека, позволяющая реализовать веб-сервер [19].
Среди многочисленных программных реализаций архитектур нейронных сетей и в частности LSTM, выделим Theano[20], а также созданную на ее основе библиотеку Keras[21]. Библиотека Keras позволяет использовать как Theano, так и TensorFlow[22] в качестве основы вычислений. Keras упрощает процесс создания нейронных сетей, предоставляя для этого специальный конструктор. В основе любого кода с использованием Keras лежит объект model, который описывает то, в каком порядке и какие именно слои содержит ваша нейронная сеть.
Для построения структуры реляционной базы данных, рассмотрим необходимые сущности и их структуру [23]. Проект (project) – объединяет ряд исследований над набором данных. В рамках проекта рассматриваются данные из определенного источника (временной ряд, который хранится InfluxDB). Все действия по преобразованию данных, построению моделей или ансамблей производятся в рамках проекта.
Источник данных (data_source) – представляет собой описание данных в источнике. В рамках хранилища рассматривается основная задача – прогнозирование временных рядов. Соответственно, информация о источнике данных включает такую информацию, как начало периода, конец периода, интервал измерений и другие.
В связи с тем, что источник данных не фиксирован, то есть данные в нем могут изменяться, дополняться, удаляться, необходимо фиксировать состояние источника данных на момент начала какого-либо исследования или ряда исследований.
Снимок данных (data_snapshot) – отражает состояние источника данных на момент времени. Однако, сами данные в исходном виде, как правило, не пригодны для построения качественных моделей, поэтому необходимо выполнить ряд преобразований.
Преобразование данных (data_preparation) – показывает способ преобразования данных (снимка данных), а также сохраняет преобразованные данные для дальнейшего применения. Преобразованные данные по-прежнему являются временным рядом, но для использования в различных нейросетях должны быть созданы конечные наборы данных в виде матрицы X и Y – объясняющие признаки и целевые значения.
Набор данных (data_set) – это конечная выборка данных, отвечающая требованиям той или иной модели. Например, одна модель может использовать для прогнозирования окно в 7 значений, а целевое (прогнозируемой) значение будет отступать на 2 пункта от окна. В этом случае размерность матрицы X – 7, а Y формируется по определенному правилу. При других параметрах выборка будет сформирована иначе, что и объясняет необходимость введения рассматриваемой сущности.
Снимок данных, Преобразование данных и Набор данных – это отдельные наборы данных, пошагово полученные из предыдущего источника. Эти данные уже не обязательно являются временными рядами с точки зрения способа хранения этих данных. В связи с этим необходимо организовать хранение этих данных в унифицированном виде. Наиболее подходящим форматом хранения является CSV (Comma-Separated Values – разделяемые запятыми значения) – текстовый формат, предназначенный для представления табличных данных. Определим также сущность CSV данные (data_csv) – это зависимая сущность, которая представляет собой только сами данные под уникальным идентификатором.
Другим не менее важным набором сущностей являются набор, связанный с нейросетевыми моделями. Исследование (research) – это группа моделей, полученных по определенным правилам. Такие правила устанавливают порядок преобразования данных, способ построения моделей и их настройки и так далее. В рамках исследования рассматриваются данные преобразованные определенным образом, поэтому все модели, построенные в ходе исследования, работают с одними и теми же данными (с точки зрения представления).
Модель (model) – это представление математической модели. Такая модель может быть, в принципе, любого типа: как нейросетевой, так и любой другой (случайный лес, логистическая регрессия и другие). Для получения модели, данные должны быть подготовлены определенным образом, как говорилось ранее, и сохранены как Набор данных. Такой набор далее и используется для обучения и тестирования модели.
В ходе описания настроек или построения модели могут возникать некоторые данные, так или иначе описывающие модель. Такие данные называются мета-данными и требуют вынесения в определенную сущность (для реляционной базы данных).
Метаданные модели (model_meta) – это простое представление данных о модели в виде «ключ-значение». Такие данные могут содержать настройки модели и/или данные о процессе обучения (ошибка, доля правильных ответов, время обучения, алгоритм обучения и другие).
Последним набором сущностей являются сущности, связанные с ансамблями (комитетами).
Ансамбль (ensemble) – это сущность, создаваемая в рамках одного проекта. Такое ограничение вводится для ограничения данных – все модели должны работать на данных одного и того же рода. Здесь описываются такие данные об ансамбле, как метод построения ансамбля, тип метамодели (мета-классификатора), математическая модель ансамбля и так далее.
Ансамбль составляется из Моделей. При этом каждая модель может содержать ряд определенных параметров с точки зрения ансамбля. Это может быть, например, вес эксперта для линейной регрессии.
Элемент ансамбля (ensemble_item) – параметризованная модель, используемая в построении ансамбля.
Физическая модель данных в MySQL представлена на рис. 1. Для связи реляционной базы данных MySQL и нереляционной InfluxDB необходимо ввести ряд спецификаций:
- измерение (measurement), содержащее экспортируемую информацию должно иметь имя «data_source»;
- измерение обязательно должно включать тег (tag) «mysql_id», содержащий идентификатор исходных данных, куда будет произведена привязка;
- тип данных значения (value) должно быть float – числом с плавающей точкой.
Измерение создается автоматически при добавлении новых данных. Рассмотрим пример добавления данных в необходимое измерение по установленным правилам: «data_source,mysql_id=234 value=0.55 1422568543702900257». Такой запрос добавит в базу данных InfluxDB запись в необходимое измерение для источника данных с идентификатором 234. Запись будет содержать значение 0.55 и привязку ко времени со значением 1422568543702900257 (timestamp) – «Thu, 29 Jan 2015 21:55:43.702900257 GMT».
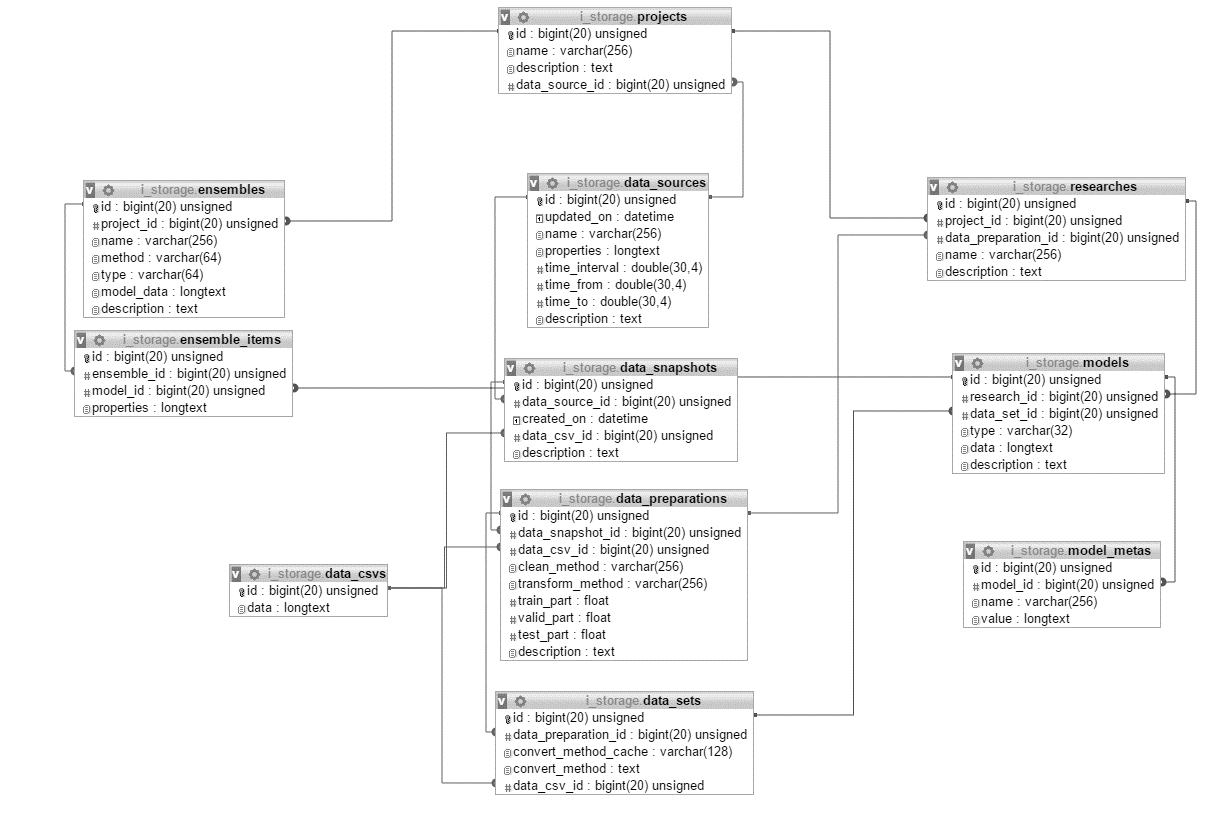
Рис. 1. Физическая модель данных в MySQL
Одна из основных задач хранилища – предоставление функционального программного интерфейса для взаимодействия с данными, хранящимися в базе данных. Поэтому помимо средств хранения данных (MySQL, InfluxDB) хранилище ансамблей нейросетевых моделей включает внутреннюю логику, определяющую правила и функционирования системы.

Рис.2. Общая схема пакетов хранилища
Рассмотрим каждый пакет из представленных на рис. 2:
- enstorage – полная библиотека хранилища. Данный пакет включает в себя основные модели объектов, отражающие сущности базы данных (ORM, Object-Relational Mapping);
- adapter – данная библиотека реализует методы преобразования данных для дальнейшего использования в моделях;
- enmyadmin – содержит основной функционал встроенной системы администрирования хранилища.
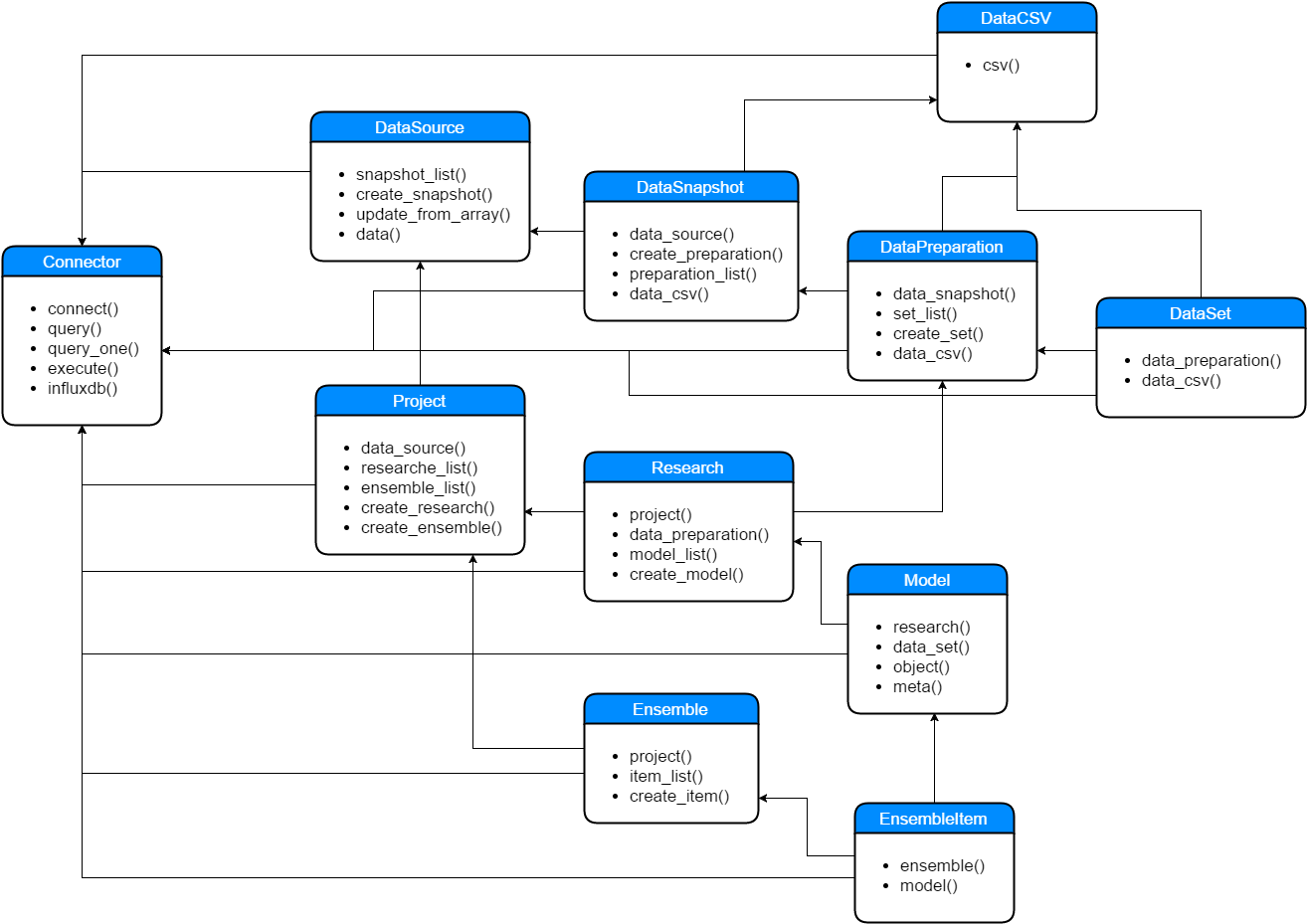
Рис. 3. Cтруктура классов хранилища enstorage
Отдельным классом, который обязательно должен быть использован перед работой с хранилищем ансамблей нейросетевых моделей, является Connector [рис.3]. Данный класс реализует подключение к необходимым базам данных (MySQL и InfluxDB). Все остальные классы являются компонентами ORM и реализуют следующие стандартные public (доступные из вне) функции:
- delete – удаление связанного с базой данных объекта;
- save – сохранение (создание или обновление) объекта базы данных;
- get – статичный метод, возвращающий объект класса, к которому он относится, по указанному идентификатору записи (id);
- get_list – статичный метод, возвращает список объектов класса, в котором вызван, по указанным идентификаторам (ids), если идентификаторы не указаны, то возвращается полный список всех объектов.
Исходные данные в InfluxDB могут обновляться и пополняться с течением времени. Для фиксации определенного набора данных необходимо создать снимок (DataSnapshot) (рис.4).

Рис. 4. Поступление и конвертация данных в хранилище
Создание снимка реализуется при помощи метода DataSource.create_snapshot(), который загружает текущее состояние источника на указанный временной период (DataSource: time_from, time_to). Загрузка данных выполняется с применением агрегирующей функции, группирующей данные по временному интервалу – DataSource.time_interval. Сохраненный снимок выступает в роли самостоятельных данных, которые могут быть использованы для дальнейших исследований.
Для подготовки данных создается объект DataPreparation, который обеспечивает хранение подготовленных данных, а также преобразование данных DataSnapshot. Создание преобразованных данных выполняется при помощи метода DataSnapshot.create_preparation(clean_method, transform_method, train_part, valid_part, test_part), где параметры (по порядку): метод заполнения пустых значений, метод преобразования значений, доля обучающей выборки, доля валидационной выборки, доля тестовой выборки. Подготовка данных в ручном режиме осуществляется методом DataPreparation.prepare().
После преобразования данных, на их основе может быть создано исследование – Research. При создании модели, Research не определяет с каким набором работает модель, это задача сервиса, использующего хранилище.
Сервис должен произвести следующий порядок действий:
- создать модель, привязанную к исследованию;
- исходя из типа модели, преобразовать нужным адаптером (adapter) данные – DataPreparation.create_set(adapter);
- сообщить модели, о созданном наборе данных посредствам Model.data_set(created_data_set).
При этом в автоматическом режиме будут обработаны адаптером преобразованные данные DataPreparation. Данный этап является завершающим для серии преобразования исходных данных, полученных из DataSource.
Еще одним важным потоком данных является информация, поступающая в ходе построения моделей и ансамблей. Фиксация таких данных (метаданных) для модели осуществляется методами Model.meta(key, value). Мета данными могут абсолютно любые данные, описывающие модель. При построении ансамбля дополнительные параметры фиксируются в свободной форме в EnsembleItem.properties. Однако рекомендуется использовать формат JSON.
Особенностью хранилища является то, что хранение объектов конечных реализаций моделей осуществляется благодаря специальному формату. Данные объектов сериализуются и десериализуются при помощи библиотеки pickle. Такой подход обеспечивает возможность сохранения и восстановления объектов целиком, тем самым обеспечивая высокий уровень интеграции пакета enstorage с другими библиотеками. Также, благодаря используемому формату, хранилище может принять не только нейросетевые модели, но и любые другие. Однако, из-за использования библиотеки pickle существует ограничение на использование этих данных в языках, отличных от Python, так как данные совместимы только с ним.
Разработка пользовательского интерфейса
Для упрощения администрирования хранилища ансамблей нейросетевых решений предусмотрен пакет enmyadmin, входящий в enstorage. Данный пакет представляет из себя веб-сервер с основными методами администрирования. Основным шаблоном проектирования веб-приложения является model-view-controller (MVC, «модель-представление-контроллер»). В роли клиентского приложения выступает HTML5-JS приложение, разработанное с использованием AngularJS [24]. Взаимодействие клиентского и серверного приложений осуществляется по технологии REST (сокр. от англ. Representational State Transfer — «передача состояния представления»), обеспечивающее независимость серверной части от клиентского приложения. Фреймворк работает с HTML, включающим дополнительные пользовательские атрибуты, которые описываются директивами, и связывает ввод-вывод области страницы с моделью, представляющей собой объекты JavaScript. Значения этих объектов задаются вручную или извлекаются из статических или динамических JSON-данных.
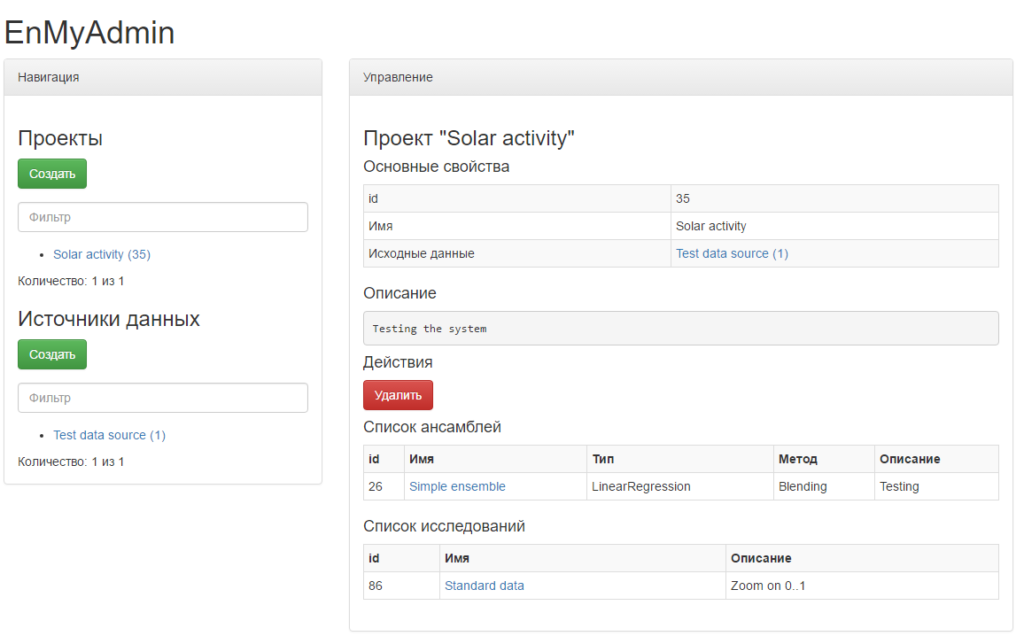
Рис. 5. Клиентское HTML приложение, реализующее интерфейс EnMyAdmin
На рис. 5. представлена форма просмотра информации о проекте. В левой части формы находится фиксированная панель навигации, позволяющая просматривать список проектов и источников данных для быстрого перехода к ним. Для поиска необходимого пункта предусмотрен функционал фильтрации. В правой части окна находится область управления, включающая элементы управления открытым объектом.
Разработаны следующие формы управления объектами: проект, исследование, модель, ансамбль, исходные данные, снимок данных, преобразованные данные, набор данных.
Важно отметить, что благодаря использованию технологии REST, клиентское приложение системы администрирования может быть разработано на любой платформе, поддерживающей взаимодействие по HTTP протоколу.
Тестирование системы на реальных данных
Для тестирования работоспособности хранилища в реальных задачах необходимо реализовать систему построения ансамблей, а также обучения моделей. Конструктор ансамблей – это отдельный функционал, который может быть вынесен в специальный пакет - endirector. Данный пакет включает методы построения ансамбля, и использует объекты хранилища из пакета enstorage. Ансамбль формируется в автоматическом режиме, исходя из настроек в Ensemble. Ниже приведен пример построения ансамбля из набора моделей, а также применение Conductor для формирования метамодели:
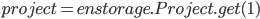
![models = enstorage.Model.get_list([3,4,5])](http://i-intellect.ru/wp-content/plugins/latex/cache/tex_9c27a876d103d2709f116a882c0bf49a.gif)
# Настройка ансамбля
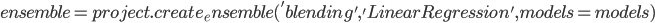
# Создание ансамбля
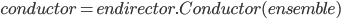
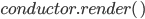
Порядок действий построения ансамбля, реализованный в методе Conductor.render(), включает в себя:
- инициализацию объекта метамодели;
- определение метода создания ансамбля;
- создание пересечения матриц данных (DataSet) всех экспертов;
- запуск алгоритма построения ансамбля;
- сохранение метамодели и параметров моделей.
Отдельно стоит отметить, что наборы данных различных моделей могут существенно отличаться друг от друга. Так, один набор данных может быть получен с задержкой в 4 значения, а другой – в 10. При этом объем выборок так же будет отличаться. Также могут использоваться другие методы конвертации временного ряда, что создаст невозможность однозначно получить результат всех моделей для одних данных. Решением данной проблемы является идентификация (id) целевых значений. Таким образом, каждый набор [X, y] в DataSet также включает и id – [id, X, y]. Благодаря этому можно получить значения всех моделей для конкретного целевого значения – y.
В качестве исходных данных для тестирования системы использованы данные о солнечной активности за период с января 1700 года по февраль 2015 года всего 303 значения [рис. 6]. Для эксперимента построим 3 нейронной сети с задержкой в 5, 7, 13 значения.
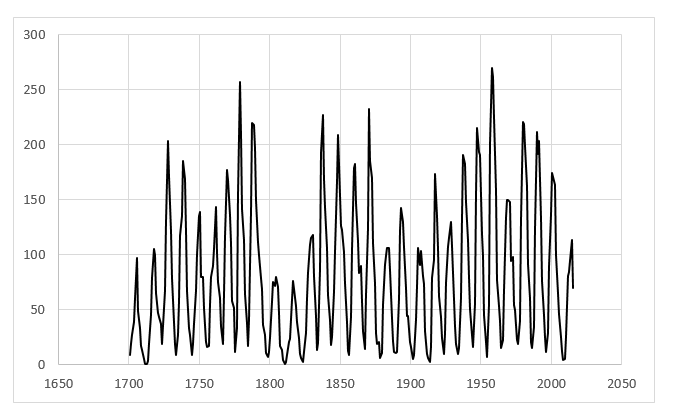
Рис. 6. Среднегодовое количество солнечных пятен
В ходе выполнения итогового скрипта выполняются следующие действия:
- подключение к хранилищу;
- получение данных о наборе данных;
- создание снимка данных;
- преобразование данных (масштабирование, выделение тестовой выборки – 30%);
- создание проекта и исследования;
- создание и инициализация модели;
- обучение моделей;
- создание ансамбля;
Код создания модели LSTM с применением библиотеки Keras представлен ниже.
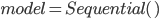
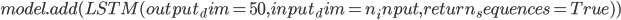
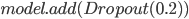
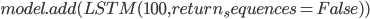
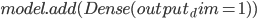
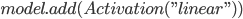
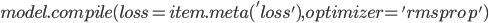
Для оценки качества каждой модели, а также ансамбля, рассчитаем среднеквадратическую ошибку (MSE) на тестовой выборке.
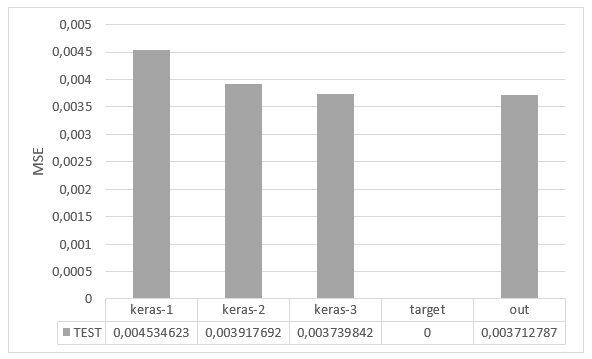
Рис. 7. Среднеквадратическая ошибка моделей и ансамбля на тестовой выборке
На диаграмме, представленной на рис. 7, видно, что наименьшее значение ошибки у ансамбля (на графике – out). Так как в качестве метамодели использовалась линейная регрессия (Linear Regression), то можно оценить вес каждой модели в результирующем значении. Данные значения записаны в EnsembleItem.properties:
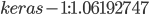 ;
;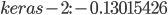 ;
;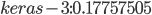 .
.
Значения весов можно интерпретировать следующим образом: наибольшим весом обладает первая модель (keras-1), небольшую корректировку вносит третья модель (keras-3), компенсацию оказывает вторая модель (keras-2). На рис. 8 представлены результаты прогноза, полученные с помощью ансамбля.

Рис. 8. График прогноза солнечной активности на тестовой выборке
Заключение
В ходе выполнения данной работы был разработан прототип системы хранения ансамблей нейросетевых моделей. Проведенный эксперимент по прогнозированию солнечной активности показал, что ошибка ансамбля нейросетевых моделей ниже, чем ошибка каждой отдельно взятой нейросетевой модели. Несомненно, для улучшения результатов прогнозирования необходимо проведение дополнительных экспериментов и совершенствование программного обеспечения.
Разработаны следующие программные решения:
- пакет для языка Python, обеспечивающий быстрое и упрошенное взаимодействие с базами данных, реализованный с использованием технологии ORM;
- разработан и реализован пакет преобразования временного ряда в конечные выборки, применяемые в моделях;
- реализован интерфейс пользователя в виде HTML приложения, обеспечивающий наглядное отображение данных и удобное взаимодействие с хранилищем ансамблей нейросетевых моделей.
Результаты проделанной работы показывают перспективность разработанных программных решений и обеспечивают высокую степень интеграции в расширяемые программные продукты на языке Python.
Литература
- Sacread’s, http://sacred.readthedocs.io/en/latest/ (дата обращения: 9.5.2016)
- Hyperopt, http://hyperopt.github.io/hyperopt/ (дата обращения: 12.5.2016)
- FGLab, https://kaixhin.github.io/FGLab/ (дата обращения: 16.5.2016)
- Luigi, http://luigi.readthedocs.io/en/stable/ (дата обращения: 11.5.2016)
- Kaggle Ensembling Guide, http://mlwave.com/kaggle-ensembling-guide/
- A Deep Learning Approach with an Ensemble-Based Neural Network Classifier for Black Box ICML 2013 Contest, http://deeplearning.net/wp-content/uploads/ 2013/03/LukaszRomaszko_ICML2013_BlackBox.pdf (дата обращения: 10.5.2016)
- О проблеме генерации разнообразия ансамблей индивидуальных моделей в задачах идентификации, http://vspu2014.ipu.ru/proceedings/prcdngs/3214.pdf (дата обращения: 13.5.2016)
- Jing Yang, Xiaoqin Zeng, Shuiming Zhong, Shengli Wu Effective Neural Network Ensemble Approach for Improving Generalization Performance // IEEE Transactions on Neural Networks and Learning Systems, 2013, vol. 24, issue: 6, pp. 878 - 887
- Ensemble of Deep Convolutional Neural Networks for Learning to Detect Retinal Vessels in Fundus Images, https://arxiv.org/abs/1603.04833 (дата обращения: 5.5.2016)
- Learning Ensembles of Convolutional Neural Networks, http://theorycenter.cs.uchicago.edu/ REU/2014/final-papers/chen.pdf (дата обращения: 10.5.2016)
- Хайкин С. Нейронные сети: полный курс, 2-е издание. : Пер. с англ. – М.: Издательский дом «Вильямс», – 1104 с.
- Belyavskiy, V. Misyura, E. Puchkov Prediction intervals for time series using neural networks based on wavelet-core // Far East Journal of Mathematical Sciences, 2016, vol. 100, issue: 3, pp. 413 – 425.
- Mohamed Akram Zaytar, Chaker El Amrani Sequence to Sequence Weather Forecasting with Long Short-Term Memory Recurrent Neural Networks // International Journal of Computer Applications, 2016, vol. 143, no.11, pp. 7 – 11.
- Deng, Li, Dong Yu, and John Platt. Scalable stacking and learning for building deep architectures // Acoustics, Speech and Signal Processing, 2012.
- MySQL, https://www.mysql.com/ (дата обращения: 2.5.2016)
- InfluxDB, https://influxdata.com/ (дата обращения: 2.5.2016)
- NumPy, http://www.numpy.org (дата обращения: 3.5.2016)
- Scikit-learn, http://scikit-learn.org (дата обращения: 3.5.2016)
- CherryPy, http://www.cherrypy.org (дата обращения: 7.5.2016)
- Theano, http://deeplearning.net/software/theano/ (дата обращения: 17.5.2016)
- Keras, https://keras.io/ (дата обращения: 10.5.2016)
- TensorFlow, https://www.tensorflow.org/ (дата обращения: 13.5.2016)
- Е.В. Пучков, Г. И. Белявский Разработка нейроэмулятора для решения задач прогнозирования и классификации // М-во образования и науки Рос. Федерации, Рост. гос. строит. ун-т. - Ростов-на-Дону : РГСУ, 2012. - 138 с
- AngularJS, https://angularjs.org/ (дата обращения: 13.5.2016)

