Prediction Intervals For Time Series Using Neural Networks Based On Wavelet-Core
The authors: Grigoriy Belyavskiy, Valentina Misyura, Evgeny Puchkov
Introduction
At the prediction for the time series there are problems of the noise, the non-stationarity, and we don’t have enough information to choose the financial market model. In this situation, the usage of an artificial neural network is justified. It allows obtaining non-linear and non-stationary models using the training algorithm and window method [1].
Consider the time series as a realization of a stochastic process 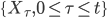 . The object of research is a discrete analogue of the equation,
. The object of research is a discrete analogue of the equation, 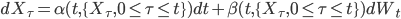 , where coefficients are time and trajectory functional of a stochastic process.
, where coefficients are time and trajectory functional of a stochastic process.
One approach of solving the time series prediction problem uses wavelet transforms and artificial neural networks (ANN), which are well described in the scientific publications [2, 3, 4, 5, 6]. In some cases, wavelet transformation is used for initial data transformation, which is submitted to the network as training examples. In other cases, network signals are transformed with wavelet-basis usage.
In this work possibility of the time series prediction using neural network model based on a wavelet-core is investigated. The problem of a confidential interval prediction is considered. The prediction of a confidential interval is more effective than the point prediction for decision making. One more feature is using the order statistics in addition to values of the time series in the training sample. The basic complexity of a problem consisted in the training algorithm. The hybrid algorithm has been used. It combines the gradient method with the genetic algorithm. The evolutionary computations are used to evaluate the gradient. It has allowed to avoid difficult computations of the gradient during iterations.
Prediction Methodology
Problem Statement
Consider the stochastic process model:
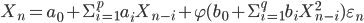 |
(1) |
where 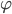 is function equal to zero outside some finite interval
is function equal to zero outside some finite interval ![[0, A]](http://i-intellect.ru/wp-content/plugins/latex/cache/tex_dfd9b2691d7a26a35923981ee45a59df.gif) and belongs to space
and belongs to space ![L_2 [0,A]](http://i-intellect.ru/wp-content/plugins/latex/cache/tex_16a694988da4d2030931578c6b00ad18.gif) ,
, 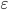 - sequence of independent, standard normal random variables. Model (1) related to conditionally Gaussian models with conditional distribution law
- sequence of independent, standard normal random variables. Model (1) related to conditionally Gaussian models with conditional distribution law 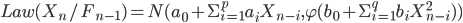 , where
, where 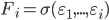 , that allows to find the joint density
, that allows to find the joint density  for fixed
for fixed 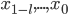 , where
, where 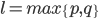 . In the particular case, when
. In the particular case, when 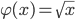 over interval , Equation (1) is
over interval , Equation (1) is 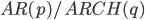 - equation [7].
- equation [7].
There is no second component of the model – stochastic volatility in the evaluation of the conditional expectation 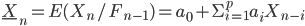 . This is the main disadvantage of the one-step prediction problem. The prediction of a confidential interval is more effective.
. This is the main disadvantage of the one-step prediction problem. The prediction of a confidential interval is more effective.
Assume that 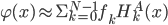 was calculated with a high degree of accuracy, where
was calculated with a high degree of accuracy, where 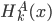 - wavelet - basis on the interval for example, Haar basis [8], built on the basis of maternal functions:
- wavelet - basis on the interval for example, Haar basis [8], built on the basis of maternal functions:
![H_0^{A} (x) = 1, x \in [0, A], H_1^{A} (x) =](http://i-intellect.ru/wp-content/plugins/latex/cache/tex_3b7b1ad4082b3b7e84306646c64c77b5.gif) ![1, x \in [0, A/2], -1, [A/2, A]](http://i-intellect.ru/wp-content/plugins/latex/cache/tex_045269722c8a5567c9778027bfccf40d.gif) |
(2) |
Then the confidence interval prediction with a fixed confidence probability 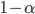 equal to
equal to
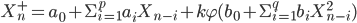 , , |
(3) |
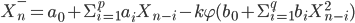 |
when 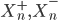 – the upper and lower predictive estimates of the stochastic process, respectively, the parameter
– the upper and lower predictive estimates of the stochastic process, respectively, the parameter 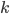 - a solution of the equation
- a solution of the equation 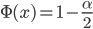 , where
, where 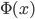 - a function of the standard normal distribution.
- a function of the standard normal distribution.
Architecture of Wavelet Neural Network
The research about neural network representation of nonlinear stochastic time series models are found in literature about neural network design and applications [9, 10, 11, 12, 13]. The complexity of this types of models is overcome by a specially selected ANN architecture and evaluating the weight coefficients. An important fact is that the weights included in the neural network model linearly. The architecture of a ANN according to equations (3) is illustrated in Figure 1.
A major advantage of the proposed solution is wavelet package included in ANN. It has allowed don’t fix the function and has made a ANN is sufficiently universal. The determination of weights is achieved by solving the problem of training.
The problem of ANN training consists of calculating the parameters 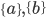 and
and 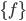 using training data set
using training data set 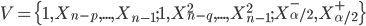 , where
, where 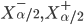 - a output values of the ANN (a lower and upper
- a output values of the ANN (a lower and upper 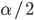 quartiles). As noted in the literature, see, eg, [14], sample quantiles have a wide range of quality properties.
quartiles). As noted in the literature, see, eg, [14], sample quantiles have a wide range of quality properties.
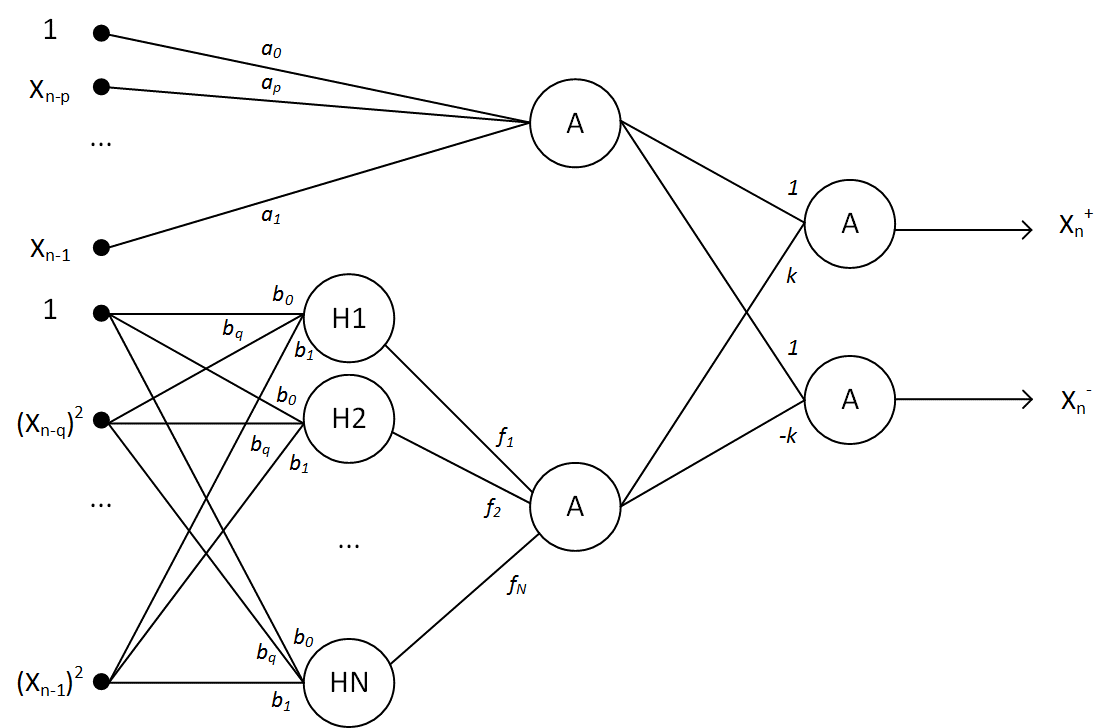
Fig. 1. Architecture of ANN based on wavelet-core
Training Algorithm
The proposed algorithm uses the idea of the adaptive algorithm described in [15 ]. The ANN is trained on training set 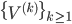 .The quality criterion of training is the mean square error:
.The quality criterion of training is the mean square error:
![min [F (\{a\}, \{b\}, \{f\}) = \Sigma_n [(X_{\alpha /2}^{n,+} - X^{+}(\{a\}, \{b\}, \{f\}, V^n))^2 + (X_{\alpha /2}^{n,-} - X^{-}(\{a\}, \{b\}, \{f\}, V^n))^2]]](http://i-intellect.ru/wp-content/plugins/latex/cache/tex_bdd2486363a2cb5b86a7f80d048e55dc.gif) |
(4) |
Let the parameter space 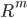 . The dimension of space
. The dimension of space 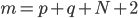 coincides with the number of adjustable parameters, including wavelet decomposition. Accordingly, the quality criterion (4) will be considered as a function of
coincides with the number of adjustable parameters, including wavelet decomposition. Accordingly, the quality criterion (4) will be considered as a function of 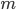 variable -
variable - 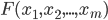 . The training algorithm was defined by the recurrent relation:
. The training algorithm was defined by the recurrent relation:
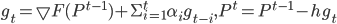 |
(5) |
where 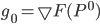 . The gradient calculation
. The gradient calculation 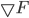 is a computationally challenging task for the considered ANN architecture. The backpropagation algorithm is one way to solve it. Another way to do it is to replace the gradient with some analogue, which is calculated more easily. For example, the partial derivative of one of the variables can be replaced by a corresponding difference:
is a computationally challenging task for the considered ANN architecture. The backpropagation algorithm is one way to solve it. Another way to do it is to replace the gradient with some analogue, which is calculated more easily. For example, the partial derivative of one of the variables can be replaced by a corresponding difference: 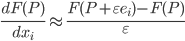 .
.
Consider the hyperplane 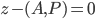 , that passes through the points
, that passes through the points 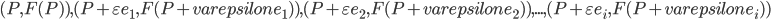 , where the
, where the  -th is vector coordinate
-th is vector coordinate  ,
, 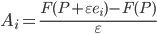 . If we generalize this fact then
. If we generalize this fact then 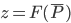 should be approximated in a neighbourhood of a point
should be approximated in a neighbourhood of a point 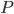 using
using 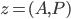 for the gradient calculation and
for the gradient calculation and 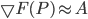 . - neighbourhood of a point is the hypercube
. - neighbourhood of a point is the hypercube 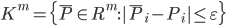 . The largest approximation error occurs at the vertices of a hypercube:
. The largest approximation error occurs at the vertices of a hypercube: 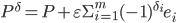 , where
, where 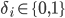 . Therefore, the calculation of the vector is necessary to consider the system of linear equations for all the vertices of a hypercube
. Therefore, the calculation of the vector is necessary to consider the system of linear equations for all the vertices of a hypercube 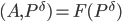 . Using the method of least squares we get a system of linear equations:
. Using the method of least squares we get a system of linear equations:
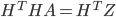 |
(6) |
where -th row of the matrix 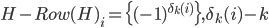 -th digit binary code of number , -th vector coordinate
-th digit binary code of number , -th vector coordinate 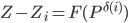 . The dimension of the system coincides with the dimension of the parameter space. The matrix size
. The dimension of the system coincides with the dimension of the parameter space. The matrix size 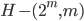 , therefore, the calculation of the system (6) may require significant computational cost.
, therefore, the calculation of the system (6) may require significant computational cost.
Consider the compromise version of calculation. We will select the set of vertices 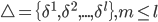 , where
, where 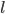 significantly less than
significantly less than 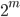 , and
, and 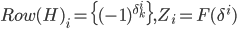 . The vertices in the set are selected by using a genetic algorithm [16].
. The vertices in the set are selected by using a genetic algorithm [16].
The algorithm of hypercube vertices selection:
- Generate a random initial population of chromosomes – binary sets. Calculate fitness function minimum
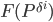 for each set
for each set 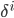 . (The less the healthier chromosome).
. (The less the healthier chromosome). - Select
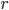 pairs for crossing with probabilities inversely proportional to the fitness
pairs for crossing with probabilities inversely proportional to the fitness 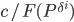 . The number
. The number 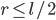 .
. - For each gene it’s been randomly determined with adjusted probability whether it will be crossed or not. If yes, there is a data exchange between parents. Thus, each pair produces 2 descendants. Calculate the fitness function for the descendants.
- Generate a new population of chromosomes using natural selection.
The algorithm will works as long as the population is stabilized. The set of hypercube vertices for a gradient calculation is constructed.
Experiments
The results of the method verification for interval prediction of stochastic processes to model data presented in [17]. Further the results of experiments on real data is presented. RTS index and S&P 500 for analysis and testing of the described method were selected. Daily index values from 11.08.2015 to 02.02.2016 for experiments was used. Predictions for sample data volume 121 observation were performed.
Data Preparation
The method of a sliding "window" with a fixed size w for the training sets in time series prediction problem was used. The univariate time series 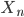 using shear procedure into two samples was converted. These are upper and lower one-step predictive estimate of a stochastic process, respectively.
using shear procedure into two samples was converted. These are upper and lower one-step predictive estimate of a stochastic process, respectively.
The lower and upper bounds of the confidence interval sample median as the target variables for training the ANN was used. The intervals using the values of the current "window" with a fixed confidence probability were found. The median is statistically stable estimation if data in the sample will stand out or differ markedly from each other [18]. The visualization of the obtained training sets are illustrated in Figure 2 and Figure 3.
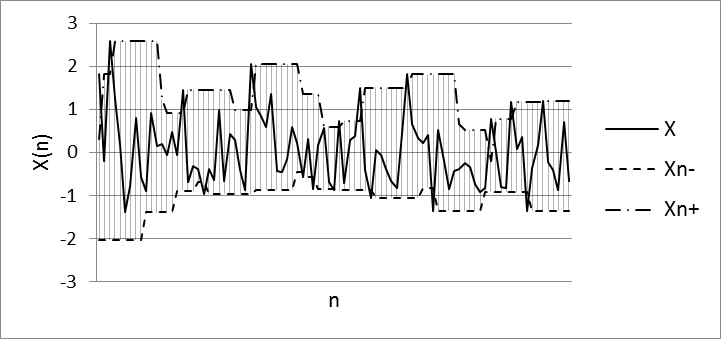
Fig. 2. RTS index training data set: w=9, α=0,2
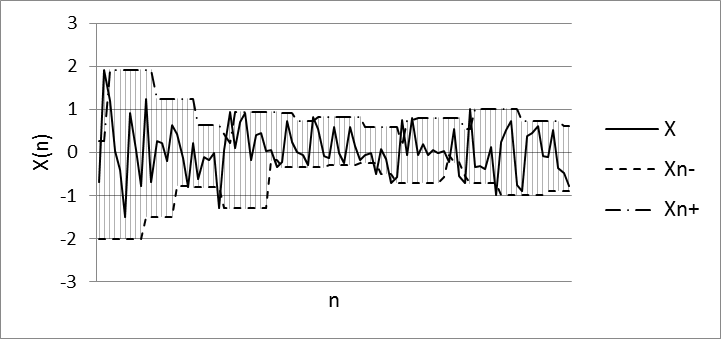
Fig. 3. S&P 500 training data set: w=9, α=0,2
Results
A original data set into two samples was splitted. The first of which is used to train ANN (100 values of training data set) and the second is used to validate the model (20 values of test data set). The window (w) size equal 9 for sample quantiles was used. Wavelet-basis contained 8 functions. The prediction results for training and test sets using the ANN is illustrated in Figures 4-7.
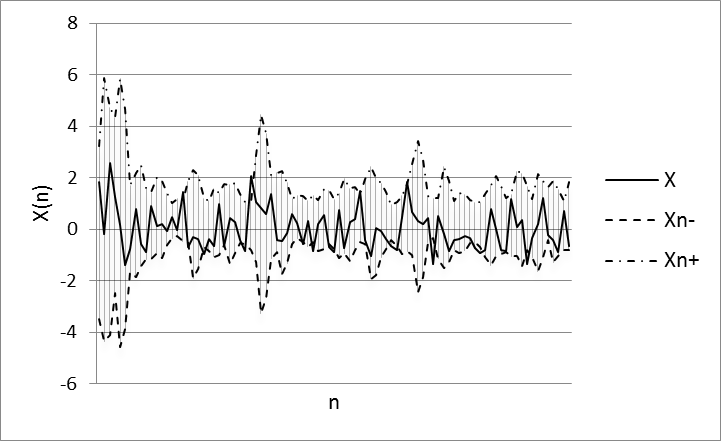
Fig. 4. Experiment results using RTS training data set.
Parameters of model: w=9, α=0,2, N=8
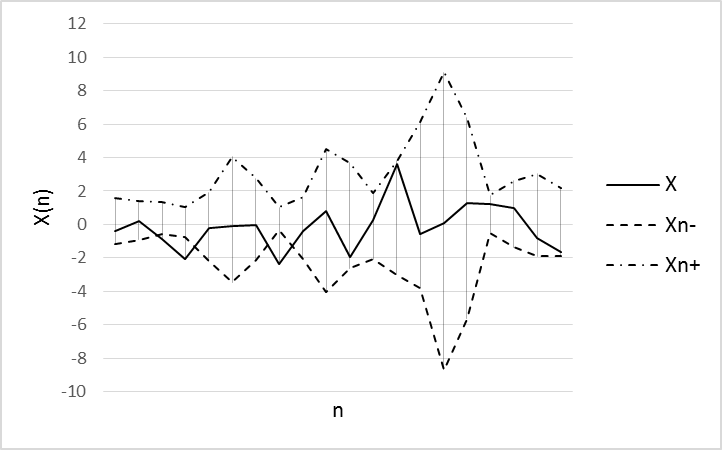
Fig.5. Experiment results using RTS test data set.
Parameters of model: w=9, α=0,2, N=8
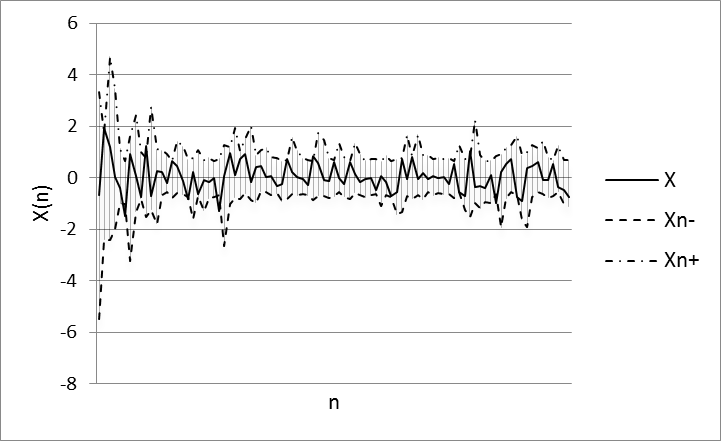
Fig. 6. Experiment results using S&P 500 training data set.
Parameters of model: w=9, α=0,2, N=8
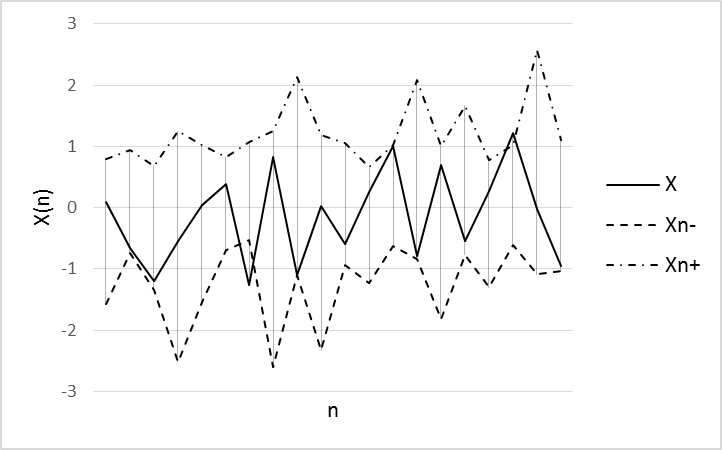
Fig.7. Experiment results using S&P 500 test data set.
Parameters of model: w=9, α=0,2, N=8
Conclusion
ANN based on wavelet-core is a fairly universal tool for time series prediction using conditionally Gaussian models. Function determines substantial non-linearity of the model. The greatest effect is achieved when the function into a rapidly convergent series in the wavelet basis is decomposed. The basic complexity of a problem consisted in the training algorithm. The hybrid algorithm has been used. It combines the gradient method with the genetic algorithm. The prediction results show expediency and efficiency of the proposed method.
References
- Li, W. Ma, Applications of artificial neural networks in financial economics: a survey, Proceedings of the 2010 International Symposium on Computational Intelligence and Design, IEEE Computer Society. 01 (2010), 211–214.
- J. Hsieh, H.F. Hsiao, W.C. Yeh, Forecasting stock markets using wavelet transforms and recurrent neural networks: an integrated system based on artificial bee colony algorithm, Appl. Soft Comput. 11 (2011), 2510–2525.
- Lahmiri, Wavelet low- and high-frequency components as features for predicting stock prices with backpropagation neural networks, Journal of King Saud University - Computer and Information Sciences. 26 (2) (2014), 218-227.
- Alexandridis, A. Zapranis, Wavelet neural networks: A practical guide, Neural Networks. 42 (2013), 1-27.
- Zhao, G. Wang, Application of Chaotic Particle Swarm Optimization in Wavelet Neural Network, TELKOMNIKA (Telecommunication Computing Electronics and Control). 12 (4) (2014), 997.
- Chen, B. Yang, J. Dong,Time-series prediction using a local linear wavelet neural network, Neurocomputing. 69, (4-6) (2006), 449–465.
- N. Shiryaev, Osnovy stokhasticheskoy finansovoy matematiki. Fakty. Modeli, FAZIS, Moscow, 1998.
- A. Zalmanzon, Preobrazovaniya Fur'e, Uolsha, Khaara i ikh primenenie v upravlenii, svyazi i drugikh oblastyakh, Nauka. Gl. red. Fiz.-mat. Lit., Moscow, 1989.
- Dente, R. Mendes, Characteristic functions and process identification by neural networks. arXiv:physics/9712035v1 [Physics data-an], 17 Dec. (1997), 11.
- Beer, P. Spauos, Neural network based Monte Carlo simulation of random processesm. ICOSSAR, G Augusti, G. Shueller, MCiampoli as ed., Millpress, Roterdam, 2005.
- Balasubramaniam, P. Vembarasan, R. Rakkiyappan, Delay-dependent robust exponential state estimation of Markovian jumping fuzzy Hopfield neural networks with mixed random time-varying delays, Commun Nonlinear Sci Numer Simulat. 16, (2011), 2109–2129.
- Leen, R. Friel, D. Nielsen, Approximating distributions in stochastic learning, Neural Networks 32 (2012), 219–228.
- Han, L. Wang, J. Qiao, Efficient self-organizing multilayer neural network for nonlinear system modeling, Neural Networks. 43 (2013), 22–32.
- Veroyatnost' i matematicheskaya statistika: Entsiklopediya, Pod red. Yu.V.Prokhorova , Bol'shaya rossiyskaya entsiklopediya, Moskva, 2003.
- I. Belyavskiy, V.B. Lila, E.V. Puchkov, Algoritm i programmnaya realizatsiya gibridnogo metoda obucheniya iskusstvennykh neyronnykh setey, Programmnye produkty i sistemy. 4 (2012), 96-101.
- N.H. Siddique, M.O. Tokhi, Training neural networks: backpropagation vs. genetic algorithms, Neural Networks 4 (2001), 2673 – 2678.
- I. Belyavskiy, I.V. Misyura, Neyrosetevoy predskazatel' s veyvlet-yadrom, Izvestiya vysov uchebnykh zavedeniy, Severo-Kavkazskiy region, Estestvennye nauki. 3 (2014), 11 – 13.
- A. David, H. N. Nagaraja, Order Statistics, 3rd Edition. Wiley, New York, 2003.

